- JPA에서 Lazy Loading과 Eager Loading의 차이점과 각각의 장단점
JPA란? Java Persistence API 이다. 자바 ORM 기술에 대한 표준 명세로,자바에서 제공합니다. 자바 애플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스 입니다. ORM기술 이기 때문에 자바 클래스와 데이터베이스 사이를 매핑합니다.
ORM(Object-Relational Mapping)이란? 객체 지향 프로그래밍 언어를 사용해 서로 호환 되지 않는 시스템간의 데이터를 변환하는 프로그래밍 기술을 의미합니다.
>>이거왜씀? 개발자가 객체 지향언어로 데이터베이스를 관리 할 수 있게 해줍니다.
>>뭐가좋음? SQL을 쓰지 않기 때문에 개발자가 객체 지향 프로그래밍에 더욱 집중할 수 있게 해주며, 데이터베이스와 비즈니스 로직 사이의 간극을 줄여줍니다. 코드의 가독성도 올려주며 유지보수를 더 쉽게하고 데이터베이스와의 의존관계를 느슨하게 해줍니다.
API = 응용프로그램 프로그래밍 인터페이스 응용 프로그램 사이에 서로 통신하여 데이터를 주고받을 때 어떤 식으로 데이터를 주고받을지 정리해놓은 규칙과 프로토콜입니다.
JPA에서는 @ManyToOne 으로 연관관계가 설정된 2개의 Entity가 존재한다면 데이터베이스의 입장에서는 Join 연산이 필요합니다. 예를들면 Member와 Board 엔티티 사이에 Board쪽에 N:1 연관관계가 존재한다면 Board 엔티티에는 Member객체를 참조하고 있을것입니다. 하지만 이는 엔티티 입장에서의 참조이고 실제 데이터베이스 에서는 Board 엔티티를 조회할때 Member 엔티티도 함께 조회하게 됩니다.
문제는 이런 조회방식은 성능조회를 야기할 수 있습니다.
>>어왜요?? Board 엔티티의 정보만을 조회하려 했는데 연관관계로 설정된 Member 엔티티도 조회하기 때문
그렇다면 N:1 로 연관관계 매핑된 엔티티를 조회할때 연관된 엔티티를 조회하지 않으려면 어떻게 해야할까요?
일단 위에서 설명한 조회 방법은 즉시 로딩으로 연관된 모든 엔티티를 한꺼번에 가져온다는 장점이있지만 엔티티간의 관계가 복잡해진다면 성능저하를 야기 할 수도 있습니다. JPA에서 연관관계의 데이터를 어떻게 가져올지를 fetch 라고 하는데요 연관관계의 어노테이션 속성으로 'fetch'모드를 지정할 수 있습니다.
fetch의 모드를 변경함으로 즉시로딩에서 '지연 로딩'으로 fetch모드를 변경 할 수 있습니다. 이 모드를 사용함으로 지연로딩을 활성화 시킬수 있습니다.
연관관계의 디폴트 값:
@XToOne: EAGER
@XToMany: LAZY
지연로딩과 즉시로딩 둘다 데이터베이스나 ORM에서 관련 데이터를 가져오는 방식이다. 둘 다 특정 객체의 연관된 데이터를 언제 가져올지에 대한 전략을 다룹니다.
이 방식은 연관관계를 설정할때 fetch 모드 설정을 수정해 설정할 수 있습니다.
지연 로딩: 실제로 데이터가 필요할 때 데이터를 가져오는방식
즉시 로딩: 데이터를 요청할 때 즉시 모든 연관된 데이터를 한꺼번에 가져오는 방식
지연 로딩의 장점
- 필요할 때만 데이터를 가져오기때문에 메모리 사용량을 줄일 수 있습니다.
- 연관되어 있는 모든 데이터를 가져오는 것이 아니기 때문에 성능이 향상될 수 있습니다.
지연 로딩의 단점
- 지연 로딩은 데이터 접근시 추가적인 데이터베이스 쿼리가 발생할 수 있습니다.
- 연관된 데이터가 많을 경우 데이터들이 호출 될때 각각의 데이터를 가져오느라 많은 쿼리가 생기는 N+1문제를 야기할 수 있습니다.
즉시 로딩의 장점
- 즉시 모든 데이터를 가져오기 때문에 추가적인 데이터베이스 쿼리가 발생하지 않습니다.
즉시 로딩의 단점
- 엔티티간의 관계가 복잡해지면 조인으로 인한 성능 저하가 나타날 수 있습니다.
- JPA에서 N+1 문제를 해결하기 위한 방법
JPA에서 N+1 문제란 무엇인가?
원치않는 데이터베이스 조회 쿼리가 추가로 생기는 문제.
JPA에서 N+1 문제는 언제,왜 일어나나?
- 연관관계가 있는 테이블에서 한쪽 테이블만 먼저 조회하고 다른테이블을 따로 조회 할 때 일어난다.
N+1은 즉시로딩/지연로딩에서만 일어나는 문제인가?
>아닙니다 N+1문제는 즉시로딩이나 지연로딩에서만 일어나는 문제가아닙니다. 즉시로딩이나 지연로딩 둘다 일어날 수 있습니다.
JPA에선 N+1 문제를 어떻게 해결하나?
>FetchJoin은 하나의 해결방법으로 한번의 쿼리로 부모와 자식 엔티티를 함께 조회 할 수 있습니다. 다만 FetchType을 무시하기 때문에 지연 로딩을 사용할 수 없고 하나의 쿼리문으로 가져오다 보니 페이징 단위로 데이터를 가져오는것이 불가능합니다. 페치 조인은 JPQL로 사용해야 합니다.
JPQL이란? JPA에서 지원하는 SQL을 추상화한 객체 지향 쿼리 언어로 SQL을 추상화 했기 때문에 특정 데이터베이스에 의존하지 않고 테이블을 조회하는 쿼리인 SQL에 반해 JPQL은 엔티티 객체를 대상으로 쿼리하는 차이가 있다.
@Query("select m from member m join fetch m.team")
List<Member> findAllJoinFetch();
과 같이 두테이블을 Fetchjoin하는 쿼리를 직접 작성하는 것이다.
FetchJoin을 하면 왜 페이징 기능을 사용할 수 없나?
>페이징을 위해서는 SQL의 LIMIT이나 OFFSET을 사용해 쿼리 결과를 제한해야 하는데 JoinFetch를 사용하면 데이터 중복이 생기기 때문에 JPA가 중복된 결과의 의도를 파악하지 못해 정확히 페이징하지 못하게됩니다. 예) User1명이 Order3개를 가지고있고 LIMIT 5를 적용하면 중복된 결과를 기준으로 5개를 가져오기 때문에 의도한 부모 엔티티만 정확하게 페이징하지 못하게됨.
그럼 어떤방식으로 해결해야하나?
>BatchSize를 활용하면 됩니다. BatchSize는 하이버네이트가 제공하는 어노테이션으로 사용하면 연관된 엔티티를 조회할때 지정된 size만큼 in 절을 사용해 조회하기 때문에 N+1문제의 엄청난 양의 쿼리를 아주 큰 폭으로 줄일수 있습니다. 배치사이즈는 지연로딩도 사용할 수 있고 페이징도 가능하기 때문에 좋습니다.
다만 배치사이즈는 너무 커도 좋지 않고 너무 작아도 좋지 않기 때문에 적절한 값 (200~1000으로 알려짐) 으로 설정한뒤에 최적화 과정을 거치는게 좋습니다.
- Fetch Join은 JPQL에서 지원하는 문법으로 즉시로딩과는 다르게 내가 필요할 때 동적으로 가져오는 기능을 지원한다. 멤버와 팀을 예로들면 멤버와 팀에서 같은 값을 가지는 녀석들을 INNER JOIN해서 가지고 옵니다. 조금 더 설명하면 멤버를 SELECT하는 쿼리가 나가고 이때 단서가 붙는데 찾아온 멤버 엔티티의 TEAM_ID를 가지는 TEAM엔티티를 JOIN해서 가져오는 것입니다. 대부분의 문제는 FetchJoin으로 해결 할 수 있으나 컬렉션을 FetchJoin하는 경우에 데이터의 정합성에 문제가 생겨 페이징 기능을 사용 할 수 없습니다. 또 1:N 관계가 두개이상 있는경우에도 Fetch Join을 사용할 수 없습니다.
- 이 문제 때문에 JPA에서 N+1 문제를 해결 하기 위해서 BatchSize를 활용 할 수 있습니다 BatchSize는 JPA에서 지원하는 기능으로 지연로딩을 할때 BatchSize의 크기만큼 where 절에서 "in" 으로 가져오기 때문에 N+1 보다 훨씬 줄어든 쿼리 갯수로 데이터를 가져올 수 있습니다. 또한 지연로딩을 사용 했기 때문에 (FetchJoin을 사용하지 않았기때문에) 페이징 처리도 온전히 가능합니다.
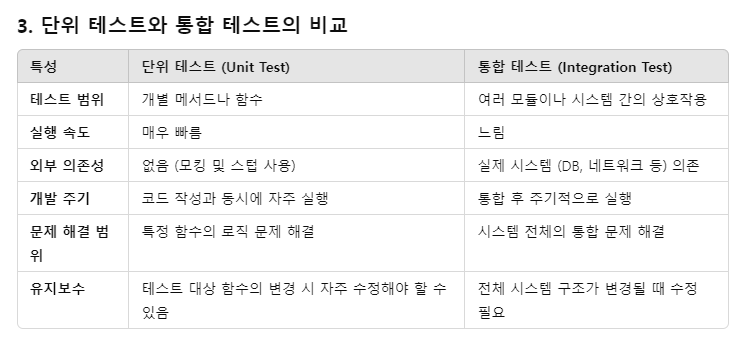
- 단위 테스트와 통합 테스트의 차이점과 각각의 장단점
단위 테스트는 애플리케이션의 가장 작은 단위, 즉 개별 함수나 메서드를 테스트하는 것을 말합니다. 주로 비즈니스 로직을 가진 메서드 하나를 독립적으로 테스트하여, 해당 메서드가 의도한 대로 동작하는지 확인합니다.
특징
- 고립된 테스트: 외부 의존성(데이터베이스, 네트워크 등)을 배제하고, 대상 함수만을 테스트합니다. 외부 의존성을 모킹(mocking)하거나 스텁(stubbing)하여 테스트를 수행합니다.
- 빠른 실행: 외부 시스템에 의존하지 않으므로 매우 빠르게 실행됩니다.
- 개발 단계에서 사용: 코드 작성 시 바로바로 테스트 가능하여, **TDD(Test Driven Development)** 테스트 주도 개발에서 많이 사용됩니다.
장점
- 빠른 피드백: 단위 테스트는 실행 속도가 매우 빠르며, 코드에 작은 변화가 생겼을 때 빠르게 결과를 확인할 수 있습니다.
- 간단한 디버깅: 테스트 대상이 개별 함수나 메서드이므로 문제 발생 시 해당 코드에만 집중할 수 있어 디버깅이 쉽습니다.
- 비용 절감: 문제가 발생했을 때 초기에 잡을 수 있어, 나중에 발생할 수 있는 큰 문제를 예방할 수 있습니다.
단점
- 제한된 범위: 개별 함수의 로직만 테스트하므로, 시스템 전체의 동작이 제대로 이루어지는지에 대한 보장은 없습니다.
- 외부 시스템 검증 불가: 데이터베이스, 파일 시스템, API와 같은 외부 의존성을 포함한 테스트는 어렵습니다.
- 테스트 유지보수: 코드가 변경될 때마다 테스트 코드도 함께 수정해야 할 수 있습니다.
- 통합 테스트는 여러 컴포넌트나 모듈을 통합하여 상호작용을 테스트하는 것입니다. 실제 환경에서 애플리케이션의 다양한 부분들이 정상적으로 협력하여 동작하는지 검증하는 것이 목표입니다.
특징
- 실제 환경에서의 테스트: 실제 데이터베이스, API, 파일 시스템 등과 같은 외부 시스템과 상호작용을 테스트합니다.
- 종속성 있는 테스트: 시스템의 여러 컴포넌트가 상호작용하는 방식과 이를 종합적으로 테스트합니다.
- 더 긴 실행 시간: 외부 시스템과의 연결 및 데이터 처리가 포함되므로 단위 테스트보다 시간이 더 오래 걸릴 수 있습니다.
장점
- 실제 환경 검증: 애플리케이션이 외부 시스템과 제대로 상호작용하는지 검증할 수 있습니다. 이는 단위 테스트에서 검증할 수 없는 부분입니다.
- 통합 문제 식별: 시스템의 여러 부분이 실제로 결합되어 제대로 동작하는지 확인할 수 있으므로, 모듈 간 통합 문제를 발견할 수 있습니다.
- 신뢰성: 실제 데이터베이스와 같은 환경에서 테스트하기 때문에 프로덕션 환경에서 발생할 수 있는 문제를 더 잘 감지할 수 있습니다.
단점
- 느린 실행 속도: 외부 시스템과 상호작용하므로 단위 테스트에 비해 실행 속도가 느립니다.
- 복잡한 디버깅: 여러 컴포넌트가 통합되어 동작하므로, 문제가 발생하면 원인을 찾는 데 시간이 걸릴 수 있습니다.
- 환경 설정 필요: 실제 데이터베이스, API 등과 연동하려면 설정 및 준비 작업이 필요하며, 환경에 따라 테스트 결과가 달라질 수 있습니다.
- QueryDSL을 사용하여 복잡한 동적 쿼리를 작성하는 방법
QueryDSL이란?
QueryDSL은 SQL을 자바 코드로 안전하고 간결하게 작성할 수 있는 도구로, 타입 안전성과 유연성을 제공합니다. 특히 ORM과 함께 사용할 때, 코드로 SQL을 작성하면서도 컴파일 시점에 오류를 잡아낼 수 있는 장점이 있습니다.
QClass란?
엔티티와 같은 패키지에 자동으로 생성됨
Entity 클래스의 메타 정보를 담고 있는 클래스
타입 안정성(Type safe)을 보장하면서 쿼리를 작성할 수 있음
컴파일 시점에 쿼리 오류를 확인할 수 없는 JPQL의 단점 보완
QueryDSL은 어떻게 코드를 작성하면될까?
1. 그레이들 설정파일에 QueryDSL추가
2. 쿼리컨픽파일에 엔티티매니저를 주입받아 JPA쿼리 팩토리에 주입시킴(그래야 JPA쿼리팩토리를 사용해 QueryDSL을 사용할 수 있음) 엔티티매니저는 JPA의 핵심클래스중 하나로 엔티티의 생명주기를 관리하고 데이터베이스에 대한 CRUD 작업을 실행하는데 사용됨
3. 그 후 QClass를 이용해 엔티티를 참조(큐클래스는 엔티티와 다르게 쿼리DSL이 이해할 수 있는 방식으로 코드가 짜여져있어 컴파일 시점에도 쿼리 오류를 확인할 수 있음)
QueryDSL은 왜써야하는가?
여러 조건에 따라 다른 필터링을 적용해야 할때 QueryDSL은 매우 유용합니다. 조건이 있을 때만 해당 조건을 추가하고, 없으면 쿼리에서 제외해야 하는 동적 조건 처리가 필요하기 때문입니다.
QueryDSL은 복잡한 동적쿼리를 작성하기 위해 Prdeicate와 BooleanExpression을 사용 할 수 있습니다.
predicate는 QueryDsl의 where절에 들어가는 조건을 정의하는 논리적 표현식입니다.
BooleanExpression은 여러 predicate를 결합해 조건을 동적으로 추가할 수 있는 더유연한 방법입니다.
BooleanExpression을 활용하면 특정값이 null일때 무시하는 조건을 추가 할 수 있어 동적으로 쿼리를 작성할 수 있습니다.
JPA쿼리팩토리로 쿼리의 생성과 실행 간소화 가능
쿼리DSL은 코드 가독성이 높고 안정성이 높다, 직관적입니다.
QueryDSL을 활용하면 SQL의 JOIN,GRUOP BY,HAVING등의 복잡한 SQL연산을 간편하게 처리할 수 있습니다.
QueryDSL의 장점
타입안전성:쿼리가 컴파일 시점에 검증되므로 SQL 문법 오류가 줄어듭니다.
유연한 동적 쿼리 작성:조건에 따라 쿼리를 쉽게 동적으로 변경할 수 있습니다.
가독성: 코드가 직관적이고 유지보수가 용이합니다.
ORM통합 :JPA,Hibernate와 같은 ORM과 쉽게 통합되어 사용됩니다.
- CS 문제 : 트랜젝션
Transaction이란?
여러 작업을 하나의 논리적인 단위로 묶어서 처리하는 매커니즘이다. 내부 작업중 어느 것이 실패하면 한 트랜잭션 안에있던 결과물 모두가 Rollback되어 작업이 실행되기 전으로 되돌아갑니다.
ACID란?
- 신뢰성 높은 트랜잭션을 구축하기 위한 조건입니다.
- Atomicity(원자성)
- 트랜잭션 내의 작업들은 마치 하나의 작업처럼 모두 성공하거나 모두 실패해야 합니다. 만약 중간 단계에서 오류가 발생하면 트랜잭션 내의 모든 작업이 Rollback 되어 아무일도 일어나지 않은 상태로 돌아갑니다.
- 예) A가 B로 송금하는과정에서 이체는 성공하거나, 실패했다면 아무일도 일어나지 않아야합니다.
- Consistency(일관성)
- 트랜잭션의 수행 전후의 데이터가 데이터베이스의 규칙을 따르는지에 관한 것입니다. 트랜잭션을 통해 완료된 데이터는 데이터베이스에서 정한 무결성 제약 조건을 항상 만족해야 합니다.
- 예) 송금후 잔액이 음수가 될수는 없습니다.
- Isolation(격리성)
- 동시에 실행되는 트랜잭션들이 서로에게 어떤 영향을 미칠 수 있는지 격리 수준을 정하는 것입니다. 상황에 맞는 격리 수준을 선택하는 것이 중요합니다.
- READ_UNCOMMITTED: 다른 트랜잭션이 커밋되지 않은 데이터를 읽을 수 있음. 가장 낮은 고립 수준으로, Dirty Read 허용 Dirty Read 란? 어떤 트랜잭션에서 아직 실행이 끝나지 않은 트랜잭션에 의한 변경사항을 보게되는 경우
- READ_COMMITTED: 커밋된 데이터만 읽을 수 있음, Dirty Read는 방지하지만 Non-Repeatable Read, Phantom Read 허용
- REPEATABLE_READ: 트랜잭션 내에서 동일한 데이터를 반복해서 읽을 때 항상 동일한 결과를 보장. 자신의 트랜잭션 번호(ID) 보다 낮은 트랜잭션 번호에서 변경된(Commit 된) 것만 읽게 되고, 자신의 트랜잭션 번호보다 높은 트랜잭션에서 변경된 것은 UNDO 영역에 백업된 레코드를 읽게 된다. 때문에 Non-Repeatable Read문제는 해결했지만 Phantom Read 문제는 여전히 생긴다.
- SERIALIZABLE: 가장 엄격한 고립 수준으로, 트랜잭션을 직렬화 실행. 모든 문제는 방지되지만, 순차처리로 성능이 떨어짐
Dirty Read 란? 어떤 트랜잭션에서 아직 실행이 끝나지 않은 트랜잭션에 의한 변경사항을 보게되는 경우
Non Repeatable Read : 어떤 트랜잭션이 같은 쿼리를 2번 실행하는데 그 사이에 다른 트랜잭션이 수정/삭제를 하여 같은 쿼리에 다른 값이 나오는 경우
Phantom Read : 어떤 트랜잭션이 같은 쿼리를 2번 실행하는데 그 사이에 없던 레코드가 추가되어 같은 쿼리에 다른 값이 나오는 경우
- 지속성(Durability)
- 트랜잭션을 성공적으로 끝내면 그 결과가 항상 기록되어야 한다는 의미입니다. 로그와 트랜잭션이 완료되면 그 결과는 영구히 남아야한다는 의미입니다
스프링에서는 격리수준,롤백정책,전파와 같은 설정을 통해 적절한 트랜잭션의 범위와 세부적인 조작이 가능합니다.
트랜잭션은 락 개념으로 동시성 문제를 해결했음.
락은 데이터베이스의 특정 행이나 테이블에 접근하지 못하게 막는 매커니즘을 의미함.
락은 비관적 락과 낙관적 락으로 나뉨
비관적 락 = 데이터베이스 락 매커니즘에 의존하는 동시성 제어 방법
>충돌이 자주 일어날 것이라고 판단되는 곳에 적용,코드 실행 시 필요한 데이터 범위에 락을 사용
먼저 자원에 접근한 트랜잭션이 락을 획득하게 되고,다른 트랜잭션은 락을 획득하기 전까지 대기합니다.
사용방법->사용할 레포지토리 코드에 @Lock(LockModeType.PESSIMISTIC_WRITE) 어노테이션 부착
낙관적 락
>엔티티에 버전과 같은 필드를 추가해 값이 트랜잭션이 커밋되면 버전이 수정되어 동시성 문제를 해결함
다만 비관적 락은 락을 획득할때 까지 다른 트랜잭션은 대기 하지만 낙관적 락은 충돌 문제를 해결해야함(재시도하는 로직을 개발자가 구현해야 한다는 뜻)
사용방법-> 구현할 엔티티에 버전 명시,서비스 단에 낙관적 락을 사용하는 코드 작성(실패시 재시도 하는 로직 포함)
비관적 락
> 동시성 문제가 많이 발생하는 곳,데이터의 일관성의 중요도가 큰곳
낙관적 락
>동시성 문제가 발생하지만 매우 드문 곳,간단한 작업일 경우 적합
롤백정책
스프링의 기본적인 롤백정책은 런타임 예외상황에만 롤백을 시킵니다.
rollbackFor 키워드를 사용하면 특정 예외상황에서도 롤백하도록 설정할 수 있습니다.
@Transactional(rollbackFor=Exception.class) 어노테이션
noRollbackFor 키워드를 사용하면 특정 예외사항에서도 롤백하지 않도록 설정 할 수 있습니다.
@Transactional(noRollbackFor=RuntimeException.class)
트랜잭션 전파 속성
트랜잭션의 기본 전파 속성은 Required입니다. 트랜잭션이 있으면 '참여'하고 없으면 새로 시작합니다.
또 다른 자주 사용하는 속성으로는 Requires_new 속성으로 항생 새로운 트랜잭션을 시작하고, 기존에 진행하던 트랜잭션은 보류합니다. 자식 트랜잭션이 커밋되면 이어서 진행합니다.
가상의 시나리오를 생각해보면 할일을 저장하고 로그를 남기는 로직이 있다고 생각해봅시다.
할일을 저장하는 로직을 실행후 제대로 실행되었다면 로그를 남기는 로직이 실행됩니다. 그런데 만약 할일은 제대로 저장이 되었지만 로그를 남기는 로직에 문제가 생겨 트랜잭션 로직이 통째로 롤백되는것이 과연 맞을까요?
이런경우를 위해 Requires_new 속성이 존재합니다. 기존 할일을 저장하는 로직은 @Transaction 어노테이션을 붙이고 로그를 남기는 로직에 @Transaction(Propagation=Requires_new) 를 붙여주면 할일을 저장하는 로직과 로그를 저장하는 로직이 별개의 트랜잭션으로 동작을 하게되고 로그 로직이 예외사항이 생겨 실패해 트랜잭션이 롤백되어도 상위 메서드에서 예외처리를 잘 컨트롤해 런타임 예외가 발생하지 않으면 프로그램이 종료되지 않고 상위 트랜잭션도 롤백되지 않아 프로그램이 종료되지 않게 됩니다.
Self-Invocation 문제
@Transactional
public void processEnrollV1() {
printActiveTransaction("::: EnrollmentService.processEnrollV1()");
// 1. 수강 처리: Course 엔티티 생성
processCourse();
// 2. 결제 처리: Payment 엔티티 생성
processPayment();
// 3. 로그 처리: PaymentLog 로그 생성
try {
processLog();
} catch (Exception e) {
log.info("로그 예외 발생");
}
}
@Transactional
public void processCourse() {
printActiveTransaction("processCourse()");
// 1. 저장 - Course 저장
Course newCourse = Course.createNewCourse("newSpring");
courseRepository.save(newCourse);
}
@Transactional
public void processPayment() {
printActiveTransaction("processPayment()");
// 1. 저장 - Payment 저장
Payment newPayment = new Payment();
paymentRepository.save(newPayment);
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void processLog() {
printActiveTransaction("processLog()");
// 1. 저장 - PaymentLog 저장
PaymentLog newPaymentLog = new PaymentLog();
logRepository.save(newPaymentLog);
throw new RuntimeException("로그 예외 발생");
}
그런데 실무에서 위와 같은 코드를 만난다면 저희가 작성한 의도대로 프로그램이 동작하지 않는다는 것을 알 수 있습니다.
이 문제를 해결하려면 트랜잭션의 동작 원리에 대해 알 필요가 있습니다.
일단 트랜잭션은 스프링에서 가장 대표적으로 사용하는 AOP 입니다. 그리고 AOP를 적용한 객체는 프록시 객체로 등록됩니다. 트랜잭션도 프록시 객체를 활용한 방식으로 동작이 됩니다.
관점 지향 프로그래밍으로 객체 지향 프로그래밍을 보완하기 위해서 나온것. 객체 지향 프로그래밍은 비즈니스 로직이든 부가기능의 로직이든 하나의 객체로 분리하는데 그치고 이 기능들을 어떻게 바라보고 나눠쓸지에 대한 정의가 부족하다는 단점이 있었다.
관점 지향 프로그래밍은 핵심 비즈니스 로직과 부가 기능 로직을 분리해 코드의 간결성을 높이고 변경에 유연하게 만들며 무한한 확장이 가능하도록 만들었습니다.
문제는 @Transactional 어노테이션이 붙은 객체는 프록시 객체로 호출되고 그다음 타겟으로 하는 실제 객체가 동작하는 방식으로 실제 객체를 프록시 객체가 둘러 싸고 있는 방식으로 동작합니다.

트랜잭션도 AOP와 동일한 동작방식으로 동작한다.
그런데 대상객체가 내부에 있는 메서드를 실행하게 되면 이 객체들은 Proxy를 거치지 않기 때문에 AOP가 적용이 되지않게 되고 트랜잭션도 AOP의 일부이기 때문에 트랜잭션이 제대로 동작하지 않게됩니다. 위쪽의 예제 코드도 트랜잭션이 걸려있는 메서드내에 클래스내에 존재하는 메서드가 존재하기 때문에 트랜잭션이 제대로 동작하지 않은것입니다.

클래스 내에 트랜잭션이 걸려있는 메서드가 내부클래스의 메서드를 사용하면 AOP가 적용되지 않습니다.
때문에 이런 문제를 해결하려면 내부메서드가 아닌 외부의 클래스로 분리하면됩니다.
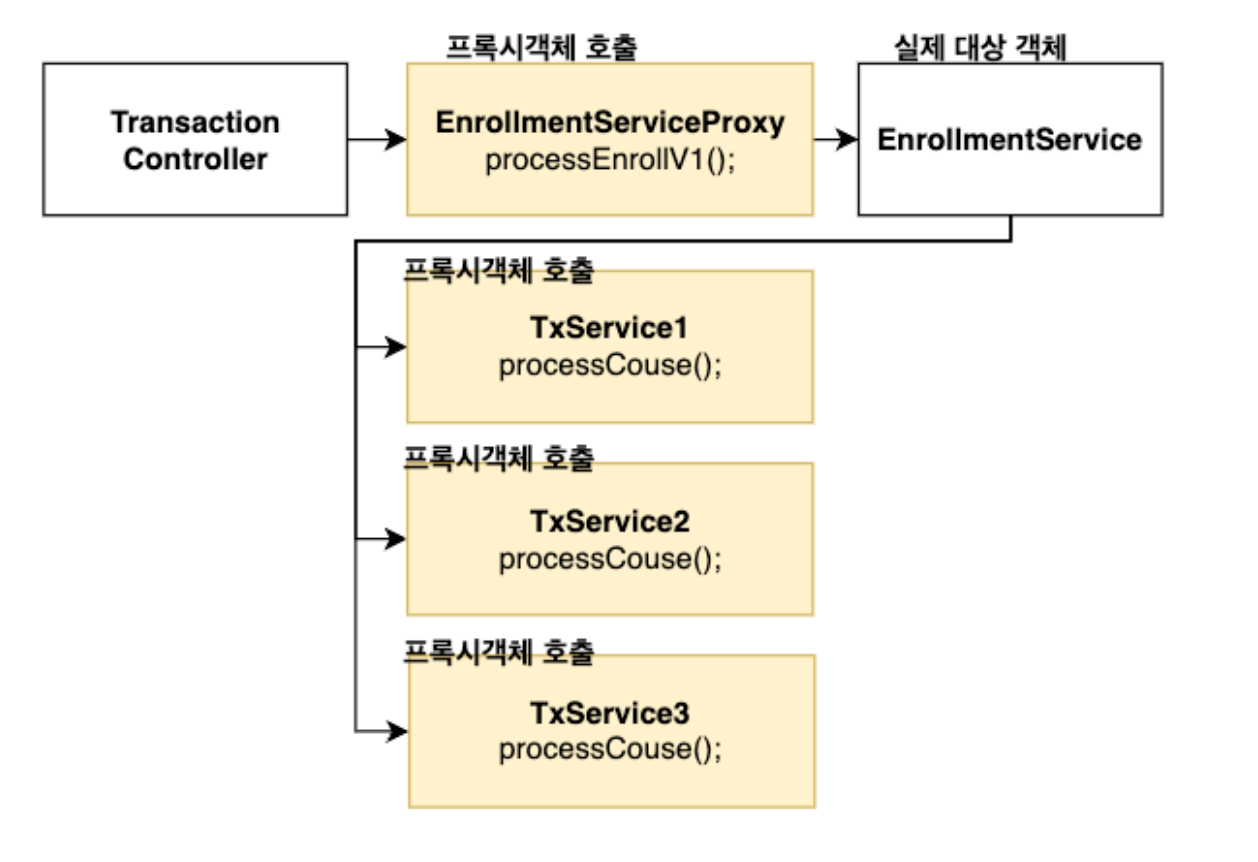
내부의 메서드는 AOP가 적용되지않는다면 외부 클래스로 분리해서 메서드를 호출하면된다.
그리고 Requires_new 키워드를 사용해 별개의 트랜잭션을 사용했다 하더라도 자식메서드에서 생긴 예외는 상위메서드로 전파 되기 때문에 상위 메서드에서 제대로 예외처리를 하지않는다면 Requires_new 키워드를 사용하더라도 모든 작업사항이 롤백되는 의도와 다른 결과를 낳을 수 있기 때문에 주의가 필요합니다.